Blokus Engine
I've always loved Board Games, so I was naturally curious to see if I could teach a computer to play one of my favorites. Along the way, I learned Rust, built the game logic from scratch, and explored reinforcement learning with transformers. For comparison, Google's AlphaZero learned to play Chess over the course of 44 million games, and this model started to pick up human-like strategies, like racing toward the center of the board, after just 15,000 games. You can check it out in the links below!

Technical Overview
This project adapts the AlphaZero algorithm to play Blokus, a four-player, perfect-information board game. The engine combines Monte Carlo Tree Search (MCTS) with deep neural networks to learn optimal gameplay through self-play.
The system uses self-play to generate training data, with the neural network learning to evaluate board positions and suggest promising moves. Training configuration and hyperparameter experiments are detailed in the project's technical report.
Some Novel Techniques
Blokus has an extremely large state action space compared to Chess or Go, so I had to come up with some novel techniques to make the game playable. Go has a 19x19 board which is relatively close to Blokus' 20x20 board. However, each move is single stone whereas blokus has many unique tiles which can all be rotated and flipped. My idea here was to reduce Blokus to a special case of Go where certain moves let a player repeatedly place tiles. In effect, players play multiple moves on their turn until they constitue a valid placement of a tile. This drastically reduces the combinatorial complexity, and every possible move can be represented in the output of the network.
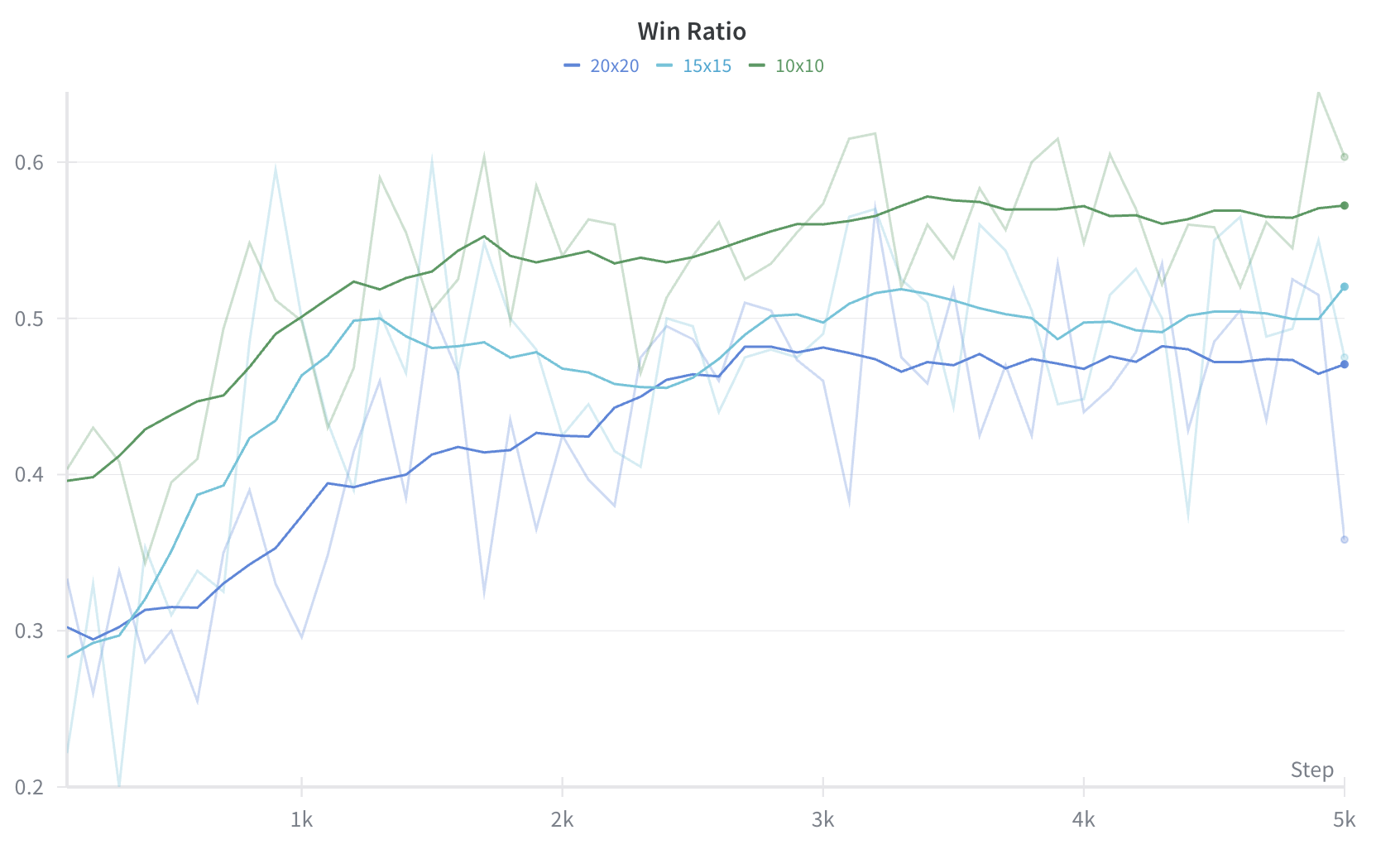
I also used a new curiculum-based learning strategy to train the model. The idea is to start with a simple game and gradually increase the difficulty of the game as the model learns. This allows the model to learn the basic concepts of the game before moving on to more complex concepts. In practice, this meant scaling up the board size from 10x10 to 15x15, then finally to 20x20. This exploits the symmetry of the game and provides the model with a clearer learning signal early on. This curriculum dovetailed nicely with the Transformer architecture which was able to scale up naturally to larger board sizes.
Lessons Learned
While I learned a lot about the technical details of AlphaZero, Transformers, Curriculum Learning, and Rust, I encountered several key challenges during the course of the project.
First, I learned first hand the dangers of premature optimization. This seemed like a great oppurtunity to learn more about Rust since I noticed that many other implementations for similar problems were written in low level languages like C++. However when I trained the model, I found that the bottleneck was copying memory between the CPU and GPU. While Rust is highly performant, I probably would have been better off using simple PyTorch tensors that are already optimized for using shared memory.
Second, I encountered the difficulty of optimizing these highly complicated algorithms in practice. The AlphaZero algorithm has many hyperparameters that affect training, and it was challenging to debug this configuration. I also underestimated the amount of compute required to solve such a problem, and I had to settle for modest gains in performance.
Try playing against the model →
Note: To host the model, I used a free HuggingFace Space, so it is not always available. I'm happy to fire it back up if you'd like to try it out.